
Les données de la recherche : un sujet stratégique



La question des données est un sujet stratégique, qui a fait l’objet d’un rapport demandé par le Premier ministre au député Eric Bothorel, « Pour une politique publique de la donnée » paru en décembre 2020. Il rappelle fortement les enjeux autour des données scientifiques comme vecteurs de connaissance. Il indique que « si [la] culture du partage entre équipes de recherche était mieux ancrée, la prise en charge et le traitement de la Covid19 auraient été certainement plus performants et plus réactifs pendant la crise. »
Le rapport de la Commission européenne Cost of not having FAIR research data paru en 2019 estime que le coût de la mauvaise gestion des données de la recherche se chiffre à 3 milliards d’euros pour la France, dû aux pertes de temps, à la non optimisation des coûts de stockage, aux frais de licence, aux problèmes de duplication de la recherche, au manque de fertilisation croisée.
L’ambition est de répondre en partie à cet enjeu stratégique par la proposition d’une plateforme nationale de données de la recherche. Cet engagement, qui figure dans le Plan national pour la science ouverte, a été réaffirmé par Frédérique Vidal, en décembre 2020 par l’annonce de la création d’ « un entrepôt des données pour stocker les données orphelines, dites de longue traîne, dont le poids en octet est faible mais dont le poids scientifique peut s’avérer majeur. Il suffit de penser à la recherche sur les maladies rares ou aux travaux des paléoanthropologues pour mesurer qu’il n’y a pas de petites données ou de données négligeables. »
Gestion des données de la recherche : une situation critique
La situation en matière de gestion des données de recherche est à l’heure actuelle relativement critique. Les consultations menées auprès des chercheurs dans le cadre des études préparatoires à ce projet font apparaître les difficultés qu’ils rencontrent : pratiques de stockage sur un support individuel (disque dur, clé USB…), perte des données au moment où un chercheur quitte le laboratoire, absence de solution pour stocker et ouvrir de manière pérenne des données collectées lors d’un projet de recherche, impossibilité de reproduire les résultats d’une recherche scientifique car les données et le code ne sont pas accessibles ou sont mal documentés et non réutilisables. Un directeur de recherche INSERM parle d’un « gouffre de données inutilisées ». La proposition présentée aujourd’hui n’est pas seulement le résultat d’une volonté politique, mais vise à répondre aux difficultés quotidiennes des chercheurs.
Données de la recherche : un enjeu économique majeur
Les enjeux économiques qui entourent les données de recherche sont très importants. Sur les 24 millions de données ayant un DOI attribué par Datacite, les plus gros acteurs (dont le nombre de DOI attribués dépasse 1 million) sont de très grands organismes de recherche (CERN, ETH Zurich) et des géants de l’édition scientifique (Figshare qui appartient au groupe Springer Nature, Sage Publishing). La France, quant à elle, n’a enregistré que 225 000 DOI. Amazon a créé un « Open data sponsorship program », qui propose l’accès gratuit à un certain nombre de services dès lors que l’on dépose des jeux de données ouverts. De géants du numérique ont lancé des moteurs de recherche de données (Google data search, Mendeley Data, ce dernier appartenant au groupe Elsevier). Le groupe Elsevier ne se présente plus comme un éditeur, mais comme une entreprise « d’analyse de données », désormais présente sur tout le cycle de vie de la recherche.
Une prolifération des entrepôts de données en France et dans le monde et pourtant une absence de solution pour de nombreuses communautés scientifiques
Dans le cadre des travaux préparatoires à la nouvelle feuille de route des infrastructures de recherche, le questionnaire soumis aux infrastructures a fait apparaître que seulement 33% d’entre elles déclarent avoir une politique des données (qui ne couvre pas toujours l’entièreté du cycle de vie) et que seulement 28% d’entre elles pratiquent le dépôt de données dans un entrepôt. Or on observe paradoxalement une prolifération des entrepôts : on compte plus de 3 600 entrepôts dans le monde et au moins 110 en France, dont une demi-douzaine d’entrepôts institutionnels existant et plusieurs autres en cours de création. Cette prolifération réduit fortement la visibilité et la découvrabilité des données pour les chercheurs, et fait obstacle à la fertilisation croisée des données entre disciplines. Le coût technologique de création d’un entrepôt pour un établissement est estimé à 1 million d’euros sur 4 ans, coût en réalité largement mutualisable.
Impact de l’ajout de données associées aux articles en termes de citations des articles concernés : Open data citation advantage
Contrairement à une crainte ancrée relative au possible “pillage” de leurs données, ceux qui partagent les données associées à leurs articles ont un bénéfice significatif en termes de visibilité, mesurée à travers les citations. Une demi-douzaine d’études montre en effet une croissance forte des citations lorsqu’on associe des données à un papier. Il existe donc une opportunité forte pour la recherche française de renforcer sa visibilité internationale, d’autant que nous constatons par ailleurs une régression de notre pays dans le classement de la France dans la production d’articles.
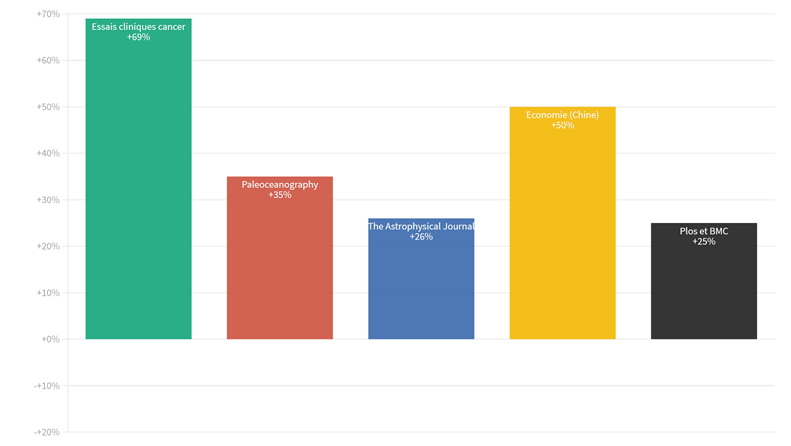
Impact de l’ajout de données associées aux articles en termes de citations des articles concernés Colavizza, Giovanni, Iain Hrynaszkiewicz, Isla Staden, KirstieWhitaker, et Barbara McGillivray. 2020. « The Citation Advantage of LinkingPublications to ResearchData ». PLOS ONE 15 (4): e0230416. https://doi.org/10.1371/journal.pone.0230416
Les chercheurs sont invités à déposer les données de leurs travaux de recherche dans des entrepôts de données. Certaines communautés thématiques ou disciplinaires ont développé des pratiques de référence en structurant leurs données en conformité avec les principes FAIR [1]FAIR : Facile à trouver, Accessible, Interopérable, Réutilisable afin de les préserver, les ouvrir ou, quand la nature ou le cadre d’obtention des données l’impose, les partager en accès restreint.
Les entrepôts nationaux et internationaux de données thématiques et disciplinaires conformes aux bonnes pratiques sont à privilégier pour la diffusion des données. Malheureusement, de trop nombreux domaines scientifiques ne disposent pas encore d’une solution adaptée pour le dépôt de leurs données.
Face à l’obligation de dépôt des données associées à leurs articles, les communautés ne bénéficiant pas d’entrepôts de confiance déposent leurs données dans les entrepôts d’éditeurs privés ou dans des entrepôts génériques non modérés.
Un service générique national de données : un engagement du plan national pour la science ouverte
Dès 2018, la Ministre de l’Enseignement Supérieur, de la Recherche et de l’Innovation annonçait parmi les mesures du plan national pour la science ouverte le développement d’un service générique d’accueil et de diffusion des données.
Afin d’évaluer le service générique national de dépôt de données le plus adapté aux besoins des chercheurs, un groupe de spécialistes issus de différents horizons disciplinaires a conduit 3 études dans le cadre du comité pour la science ouverte :
- Étude de faisabilité d’un entrepôt générique : besoins des usagers ;
- Étude comparative des services nationaux de données de 6 pays : Australie, Norvège, Pays-Bas, Canada, Royaume-Uni, Allemagne ;
- Ambitions du service et scénarios de mise en œuvre.
Il ressort de l’expression des communautés de recherche auditionnées lors de ces études que l’attente la plus forte porte sur l’accompagnement à la préparation et à la description des données.
Prendre connaissance du projet Recherche Data Gouv en cours de dévelopement
References